Arm's New Cortex-A78 and Cortex-X1 Microarchitectures: An Efficiency and Performance Divergence
by Andrei Frumusanu on May 26, 2020 9:00 AM EST- Posted in
- SoCs
- CPUs
- Arm
- Smartphones
- Mobile
- GPUs
- Cortex
- Cortex A78
- Cortex X1
- Mali G78
The Cortex-A78 Micro-architecture: PPA Focused
The new Cortex-A78 had been on Arm’s roadmaps for a few years now, and we have been expecting the design to represent the smallest generational microarchitectural jump in Arm’s new Austin family. As the third iteration of Arm's Austin core designs, A78 follows the sizable 25-30% IPC improvements that Arm delivered on the Cortex-A76 and A77, which is to say that Arm has already picked a lot of the low-hanging fruit in refining their Austin core.

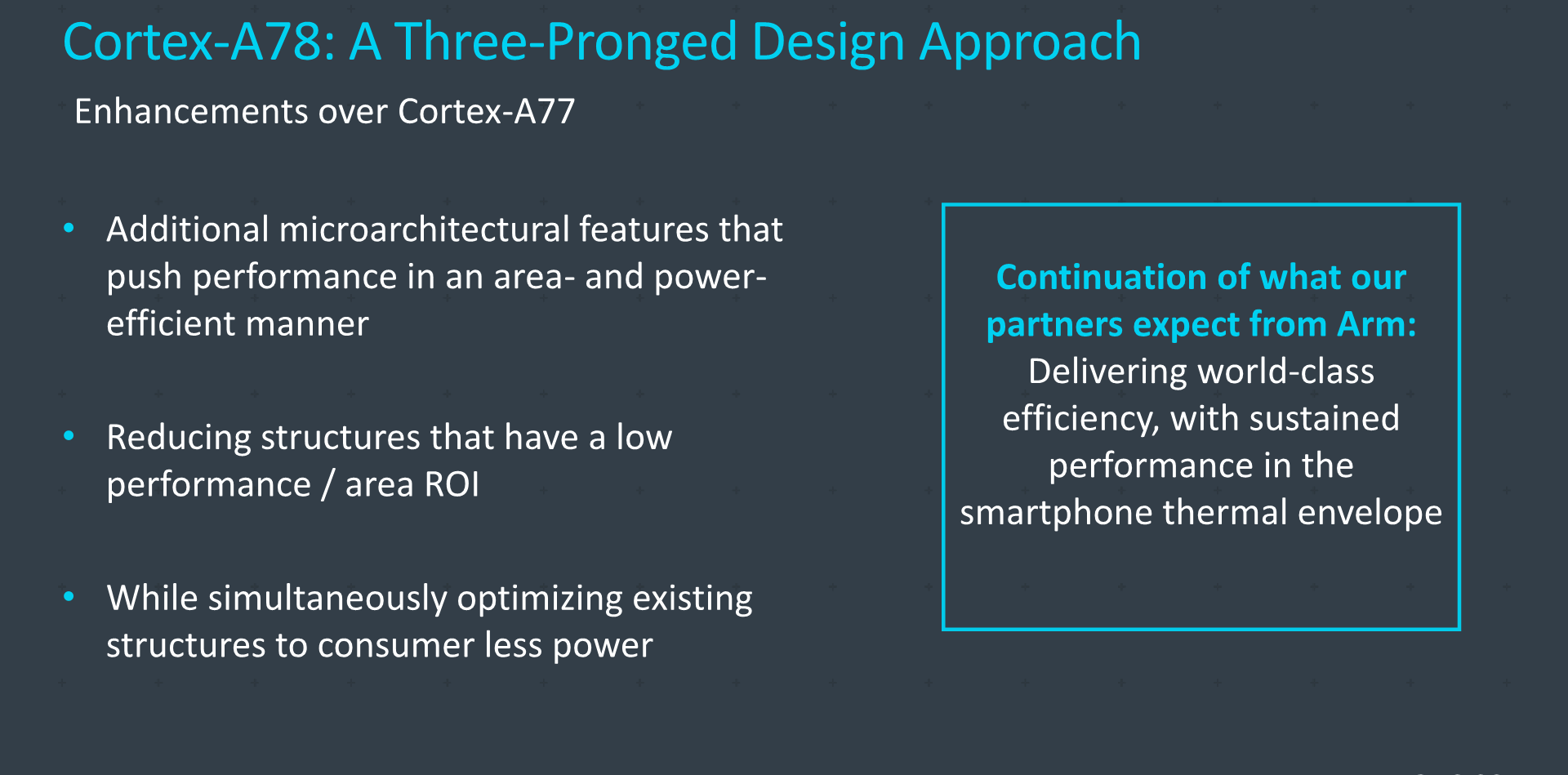
As the new A78 now finds itself part of a sibling pairing along side the higher performance X1 CPU, we naturally see the biggest focus of this particular microarchitecture being on improving the PPA of the design. Arm’s goals were reasonable performance improvements, balanced with reduced power usage and maintaining or reducing the area of the core.
It’s still an Arm v8.2 CPU, sharing ISA compatibility with the Cortex-A55 CPU for which it is meant to be paired with in a DynamIQ cluster. We see similar scaling possibilities here, with up to 4 cores per DSU, with an L3 cache scaling up to 4MB in Arm’s projected average target designs.

Microarchitectural improvements of the core are found throughout the design. On the front-end, the biggest change has been on the part of the branch predictor, which now is able to process up to two taken branches per cycle. Last year, the Cortex-A77 had introduced as secondary branch execution unit in the back-end, however the actual branch unit on the front-end still only resolved a single branch per cycle.
The A78 is now able to concurrently resolve two predictions per cycle, vastly increasing the throughput on this part of the core and better able to recover from branch mispredictions and resulting pipeline bubbles further downstream in the core. Arm claims their microarchitecture is very branch prediction driven so the improvements here add a lot to the generational improvements of the core. Naturally, the branch predictors themselves have also been improved in terms of their accuracy, which is an ongoing effort with every new generation.
Arm focused on a slew of different aspects of the front-end to improve power efficiency. On the part of the L1I cache, we're now seeing the company offer a 32KB implementation option for vendors, allowing customers to reduce area of the core for a small hit on performance, but with gains in efficiency. Other changes were done to some structures of the branch predictors, where the company downsized some of the low return-on-investment blocks which had a larger cost on area and power, but didn’t have an as large impact on performance.
The Mop cache on the Cortex-A78 remained the same as on the A77, housing up to 1500 already decoded macro-ops. The bandwidth from the front-end to the mid-core is the same as on the A77, with an up to 4-wide instruction decoder and fetching up to 6 instructions from the macro-op cache to the rename stage, bypassing the decoder.
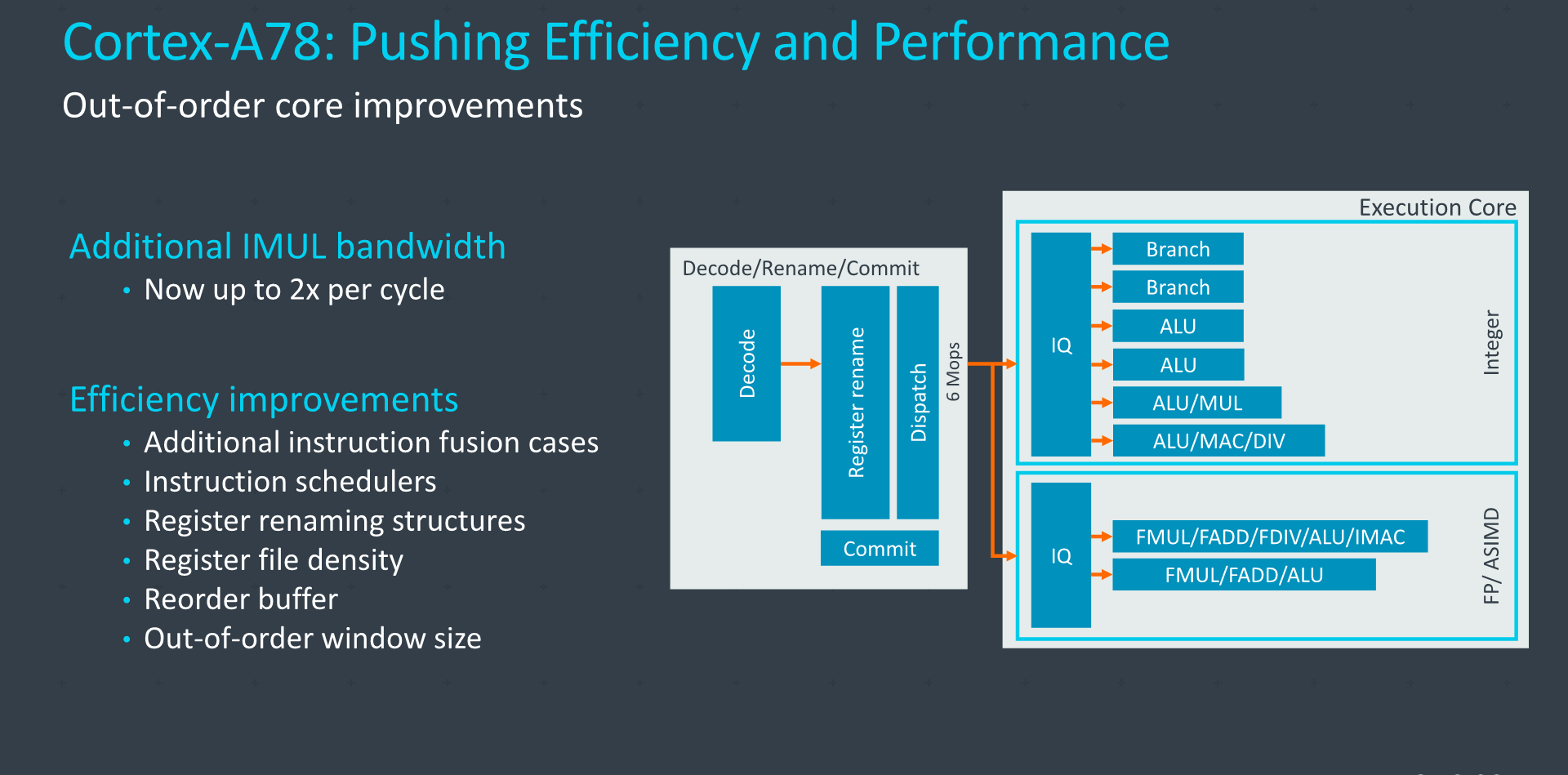
In the mid-core and execution pipelines, most of the work was done in regards to improving the area and power efficiency of the design. We’re now seeing more cases of instruction fusions taking place, which helps not only performance of the core, but also power efficiency as it now uses up less resources for the same amount of work, using less energy.
The issue queues have also seen quite larger changes in their designs. Arm explains that in any OOO-core these are quite power-hungry features, and the designers have made some good power efficiency improvements in these structures, although not detailing any specifics of the changes.
Register renaming structures and register files have also been optimized for efficiency, sometimes seeing a reduction of their sizes. The register files in particular have seen a redesign in the density of the entries they’re able to house, packing in more data in the same amount of space, enabling the designers to reduce the structures’ overall size without reducing their capabilities or performance.
On the re-order-buffer side, although the capacity remains the same at 160 entries, the new A78 improves power efficiency and the density of instructions that can be packed into the buffer, increasing the instructions per unit area of the structure.
Arm has also fine-tuned the out-of-order window size of the A78, actually reducing it in comparison to the A77. The explanation here is that larger window sizes generally do not deliver a good return on investment when scaling up in size, and the goal of the A78 is to maximize efficiency. It’s to be noted that the OOO-window here not solely refers to the ROB which has remained the same size, Arm here employs different buffers, queues, and structures which enable OOO operation, and it’s likely in these blocks where we’re seeing a reduction in capacity.
On the diagram, here we see Arm slightly changing its descriptions on the dispatch stage, disclosing a dispatch bandwidth of 6 macro-ops (Mops) per cycle, whereas last year the company had described the A77 as dispatching 10 µops. The apples-to-apples comparison here is that the new A78 increases the dispatch bandwidth to 12 µops per cycle on the dispatch end, allowing for a wider execution core which houses some new capabilities.
On the integer execution side, the only big addition has been the upgrade of one of the ALUs to a more complex pipeline which now also handles multiplications, essentially doubling the integer MUL bandwidth of the core.
The rest of the execution units have seen very little to no changes this generation, and are pretty much in line with what we’ve already seen in the Cortex-A77. It’s only next year where we expect to see a bigger change in the execution units of Arm’s cores.

On the back-end of the core and the memory subsystem, we actually find some larger changes for performance improvements. The first big change is the addition of a new load AGU which complements the two-existing load/store AGUs. This doesn’t change the store operations executed per cycle, but gives the core a 50% increase in load bandwidth.
The interface bandwidth from the LD/ST queues to the L1D cache has been doubled from 16 bytes per cycle to 32 bytes per cycle, and the core’s interfaces to the L2 has also been doubled up in terms of both its read and write bandwidth.
Arm seemingly already has some of the most advanced prefetchers in the industry, and here they claim the A78 further improves the designs both in terms of their memory area coverage, accuracy and timeliness. Timeliness here refers to their quick latching on onto emerging patterns and bringing in the data into the lower caches as fast as possible. You also don’t watch the prefetchers to kick in too early or too late, such as needlessly prefetching data that’s not going to be used for some time.
Much like the L1I cache, the A78 now also offers an 32KB L1D option that gives vendors the choice to configure a smaller core setup. The L2 TLB has also been reduced from 1280 to 1024 pages – this essentially improves the power efficiency of the structure whilst still retaining enough entries to allow for complete coverage of a 4MB L3 cache, still minimizing access latency in that regard.
Overall, the Cortex-A78’s microarchitectural disclosures might sound surprising if the core were to be presented in a vacuum, as we’re seeing quite a lot of mentions of reduced structure sizes and overall compromises being made in order to maximize energy efficiency. Naturally this makes sense given that the Cortex-X1 focuses on performance…








192 Comments
View All Comments
yankeeDDL - Tuesday, May 26, 2020 - link
If I understand correctly, the A78 has a ~20% performance lead over A77, while the X1 a ~30%?If that is the case, it seems a rather minor difference no? Nothing like the 2x (in some scenarios) of Apple's cores compared to the A77. Did I read this wrong?
SarahKerrigan - Tuesday, May 26, 2020 - link
Anandtech projects a 10-20% delta from A13 for 3GHz X1 on page 4. That's not bad IMO.syxbit - Tuesday, May 26, 2020 - link
These comments are tiring.A13 is not the benchmark. A14 will be out before any X1 chip and will trounce this.
As an Android user, I'm continually disappointed.
close - Tuesday, May 26, 2020 - link
But how would that sound? "Some percent slower than the future A14"?syxbit - Tuesday, May 26, 2020 - link
I agree. But it's not an achievement to be slower than a 1-year old chipsoresu - Wednesday, May 27, 2020 - link
It is an achievement to close the gap with a company that has a LOT more to spend on R&D.Spunjji - Wednesday, May 27, 2020 - link
It is if:1) You're gaining ground instead of losing it.
2) The 1-year-old chip in question happens to be the absolute market leader.
Vince789 - Friday, May 29, 2020 - link
It is a huge achievement as the X1 is 95% of A13 performance at only 65% power and 72% energy consumption and 146% better perf/wattWilco1 - Saturday, May 30, 2020 - link
Exactly. And it will outperform most x86 CPUs. Also, while it's the largest ever Arm designed core, it's still the smallest high-end core in the world by a mile.anonomouse - Saturday, May 30, 2020 - link
Well, one of those is measured, and one of those is a projection that also happens to bake in fabrication process improvements. I wouldn't really try to compare anything beyond the performance projection at this point.